What is SQL on Hadoop?
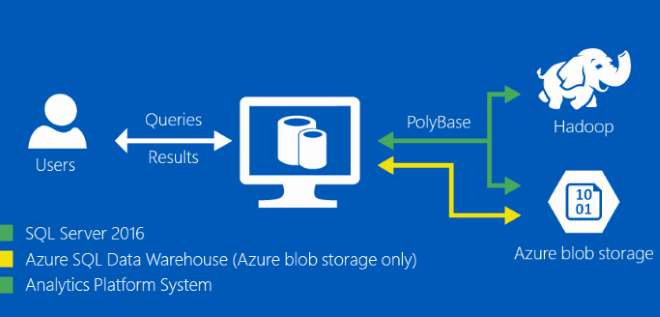
SQL on Hadoop is a framework that allows users to leverage the power of Apache Hadoop in running Structured Query Language (SQL) queries. Apache Hadoop is an open-source software platform that is designed to enable the storage and processing of large data sets across a distributed network of computers. SQL, on the other hand, is a standardized language for working with relational databases.
SQL on Hadoop provides an alternative to traditional data warehousing and analytics solutions. It enables businesses and organizations to store and analyze large amounts of structured and unstructured data in a distributed environment. SQL on Hadoop expands the use of Hadoop beyond the traditional use case of storing and processing unstructured data such as log files and social media data.
The framework allows users to use SQL commands to manipulate data stored within Hadoop. This is achieved through a number of different approaches, including the use of connectors that allow existing SQL-based tools and applications to work with Hadoop, or through the use of dedicated SQL engines that are optimized for Hadoop.
One of the key benefits of using SQL on Hadoop is the ability to leverage the scalability and performance of Hadoop to process large data sets. This is especially useful for organizations that need to analyze large volumes of data quickly, such as financial services, retail, and healthcare companies. SQL on Hadoop also allows businesses to easily integrate Hadoop into their existing technology stack and reduces the learning curve required to use the platform.
There are a number of different SQL-on-Hadoop frameworks available, including Apache Drill, Apache Hive, and Apache Phoenix. Each of these frameworks provide different levels of functionality and support for SQL queries, making it important for businesses to understand their specific requirements before selecting a framework.